I have worked in many software projects and have been lucky to be in the initial team of several software products. Besides, having acted both as a Developer and as a Product Manager has allowed me to have a wider view of what usually causes most friction between business and engineering: time estimates.

It usually starts with managers or customers asking “when will <this idea> be ready?” and it is usually followed by developers racking their brains to give a specific date… Needless to say, that date is likely to be dreadfully wrong, as it is the norm in the industry. There is a near-total inability of developers to predict how long a project will take, so time estimates are usually worthless.
However, applying Scrum along with some XP practices we can avoid the uncomfortable tension of asking developers for time estimates. Instead, we can calculate release dates automatically, getting infinitely more accurate time estimates, while saving all the arguments and keeping team morale high. How? Keep reading!
1. The problem: Time estimates in Software Projects fail dramatically
The topic of delay and over-budget in the software industry has been widely discussed, including reports such as this one by Harvard Business Review, later commented in this InfoQ post. A conclusion of this report is: “If you want to avoid the slow death caused by IT projects you must be prepared not only to spend 400% more than planned on the project, but to reap only 25% of the expected benefits. If you keep this in mind you can possibly prevent a company from being killed by an IT project”.
Moreover, since 1994 Standish Group has been releasing their CHAOS Reports every year. These reports are a relevant snapshot of the state of the software development industry. The last CHAOS Report (2015), shows that even nowadays, only 29% of Software Projects are successful (defined as on-time, on-budget and with a satisfactory result). This report highlights one of the key variables affecting success rates: the approach used to manage projects (Agile vs Waterfall). Agile approaches showed a 39% ratio of successful projects, while Waterfall only 11%. This seems to be closely related to the way in which we deal with estimates and changes in each case.
1.1. Let’s assume we never know how long it’s going to take
I bet some of you consider yourselves great estimators. However, the overconfidence of software developers is a well-known issue. Dan Milstein describes it in this great article, concluding that “one of the deepest challenges involved in writing software is the near-total inability of developers to predict how long a project will take”. In this article, Dan writes in detail about all the issues that make software projects so hard to estimate. Among others, factors such as the impossibility to write fully detailed specifications (as he says, to do so you have to be actually writing the software), uncertainty and unpredictability (about the product itself, the market, the technologies being used…) and the uniqueness of software projects (which makes it almost impossible to relate to similar projects for estimates since there are always major differences).
Moreover, in this Hacker News thread, many developers acknowledge “lying” when giving estimates, which is considered an standard practice to deal with customers or management. In the same thread, another interesting recommendation for management is to add a load factor of 2-5x to developer estimates, describing it also as an “industry standard”. As you may guess, these practices are not helping the industry to improve, but rather the opposite. Should we keep ignoring the elephant in the room?
1.2. Do we really need time estimates?
There is an increasing tendency among developers against giving estimates in software projects (see #NoEstimates). To a certain extent this makes total sense, since time estimates have been proved to fail dramatically in the industry (especially for tasks that take more than a day to complete). Besides, developers are usually the ones paying the bill of a failed estimate, by working long hours and suffering great stress due to management pressure to meet deadlines. This usually leads to poor team morale, friction, loss of credibility and many other problems, as described in detail by Richard Clayton in his article “Software Estimation is a losing game”.
On the other hand, since I have been manager and CEO apart from developer, I know how useful would time estimates be from the business side (either to calculate costs for a customer that wants a fixed-price contract; or to ourselves, to plan marketing actions, meetings, etc…). However, we must asume that calculating accurate time estimates for software projects is simply not possible. Putting pressure on developers to give us time estimates will simply make them lie to us, giving a virtually random estimate that is going to be dreadfully wrong. As we have explained before, they just don’t know how long it is going to take.
I guess I don’t need to mention that, if developers are not able to give us an accurate time estimate for a software project to be finished in; managers (with no technical background or having spent the last few years out of development) are much worse at it.
So, at this point, as a manager it is worth taking some time to think if we really need to estimate the whole project (or backlog). Maybe we could follow an alternative approach, especially if we own the product we are building. For instance, some innovative companies, such as Basecamp or Buffer are avoiding long term planning and estimation by working on 6-week cycles. They always focus on the most valuable user stories, adjusting scope to make sure a releaseable version is ready at the end of each cycle.
1.3 The role of evil contracts
If there is something to blame above anything else, that would be the magic fixed-everything contract (where price, time and scope are set at the beginning of the project). Those contracts are the root of all evil. The recipe for disaster starts by “setting the cost” of development beforehand (when we know the least about the software being built) and presenting it to the customer in the form of a contract. This contract will describe how a “fixed software” (that in most cases is just a vague idea) will be developed for a fixed price and, of course, ready for a fixed date.
That is how all this madness usually starts.
Most managers and salespeople love this approach. It seems so simple… To “calculate the cost” they just have to ask developers for time estimates, add some contingency time and then do the math (calculating salaries, other expenses, benefits…) and that’s it! Ready to convince the customer! What can go wrong?
Well, now that you know that having accurate time estimates for software projects is simply not possible, as a manager you can choose more realistic contract approaches, or you can assume the risks of doing fixed-everything contracts, based on those more-than-likely-wrong time estimates. But if you choose the latter, don’t blame developers when deadlines are not met.
If you have a team of professional and commited developers, they will be doing their best all the time, trying to do things as quickly as they can (as @dhh says, ASAP is implied). Sadly, too many times managers end up using the whip to make developers achieve the impossible. At the end, the imposible is not achieved, software quality goes down because of the rush (causing more delays due to constant bugfixing and poor code-maintainability), team morale is almost zero, everyone suffers burnout and the customer gets angry. Nobody wins.
However, even using these evil contracts, you can always follow an iterative and incremental development process internally, making sure your team is always working on the most important features and releasing an extended version of the product every few weeks. By doing this, you will always have working software to ship to your customer. If the deadline arrives and the project is not finished, at least the X more important features will be developed. And working software will be available. Moreover, if you manage to involve your customer in the process, you will benefit from showing her the incremental releases. Among other things, you will get valuable feedback, anticipate changes and build trust. Therefore, customer relationships will improve and contract changes will become easier to deal with.
2. An alternative solution to estimate Release Dates
So, if you are still forced to provide long term release dates, an alternative way to calculate them will be described in this section. This approach is based on combining Scrum with some XP concepts, such as Velocity and User Stories; as well as using effort-based Story Points.
Unfortunately, Scrum has become kind of a buzzword in the last few years and many people in the software industry say they use Scrum when in reality they are not following many of its key principles… If you are new to Scrum, I encourage you to read The Scrum Guide which is a fantastic 16-pages document written by the creators of the framework describing its principles. You can also find information on XP practices here. Too tired to read? Then a good alternative are these great videos about the scrum framework.
Although I think Scrum is a great framework for software development, I agree with Jason Fried and some others that are showing concerns about the word ‘sprint’. As they have highlighted, this term can be misinterpreted, leading to behaviors that go against sustainable development, a core agile principle. For that reason, in this article I have decided to use the word ‘cycle’ instead.
Having these definitions clear, all you need to do to get more accurate release dates for your software project is to follow 4 simple steps I will describe below. Since you won’t have to ask developers for time estimates, you will avoid many misunderstandings. Besides, this approach allows you to rearrange the product backlog anytime (adding, removing or moving stories), getting approximate release dates automatically.
2.1. Create a Product Backlog with User Stories as a first step
Not asking anything to developers yet; no coding. Sit down with your product team, potential users or customers and try to describe what you think the product should be, according to what you have learned so far. If you haven’t done it yet, creating some simple wireframes, discussing them lightly and iterating a bit over them is usually the best way to start. But keep it simple, following Lean Startup advice. This exercise will help you with customer discovery, clarifying your initial hypotheses.
So, once you have enough information about the product and its market to do so, define some core User Stories and prioritize them, creating a Product Backlog for your Minimum Viable Product (MVP). It should represent a basic version that you are able to release quickly, to get feedback from the market and keep learning and adapting, following an iterative and incremental development process. Since user stories are about functionality, wireframes are usually very good help. They can be added as part of their Acceptance Criteria.
My favourite tool for managing Scrum is Jira, which includes a great backlog-management tool. However, there are many other tools available, including Trello, which I also use as a kanban board for smaller projects. For wireframing, there are also many good tools available. One of my favourites is WireframeSketcher, due to its IDE and CVS integration. Balsamiq and Moqups are great alternatives too.
After creating the initial Product Backlog, you will have a much clearer picture of the MVP you are going to build; therefore, you will be in a better position to present it to developers.
2.2. Estimate all User Stories in the backlog based on effort points
Once you have created your initial Product Backlog and prioritized its user stories, it is time to have the first Product Backlog Refinement meeting with the Scrum Team (which includes the Development Team). Our goal would be to estimate all user stories in the backlog, but instead of time we will be using effort points. Each user story will have X points. A common approach is to use the Fibonacci scale for those points.
Since it is very important to be consistent when estimating user stories, I usually encourage the team to find the easiest user story in the backlog and give it a 1 and then find the hardest one and give it either a 13 or a 21. That way you have created the team’s effort scale, making it easier to estimate the remaining user stories based on a scale that is totally dependent on the project.
“But those effort-points are not useful for me!”, a manager said. Please, hold on. They definitely are. For now they tell you which are the easiest user stories and which ones are the hardest. But even better, in a few cycles they will help you estimate when might the project be finished or when will a specific user story probably be done, according to its place in the backlog. And this estimate will be much more precise than any you could get from asking developers for time estimates.
If in the future new user stories appear (they will), all you have to do is add them to the backlog, placing them according to their relative priority compared to the rest; and save some time to conduct a backlog refinement meeting, in which the new stories will be estimated. The most important task of the Product Owner (your role in Scrum) is to keep the backlog updated, estimated and prioritized; in order to make it useful for predicting possible release dates.
2.3. Keep effort-based estimates time-independent
Even though agile implementations usually replace time estimates by effort points (using scales such as Fibonacci or t-shirt sizes), some managers simply establish a link from those points or sizes to “their equivalent” in time. And they usually do that publicly, which means that everybody goes back to time estimates, thus ruining the whole thing again and making developers hate agile too (even though what they hate is a bad implementation of agile frameworks).
The key of using an effort-based system for story points is precisely to keep estimates separated from time. The relative “effort” of a task is a much easier concept to analyze for developers, especially when comparing different user stories of a project. Moreover, estimating effort instead of time prevents common conflicts, mostly related to considering time estimates a “contract”. As we have seen before, developers simply cannot estimate how long a software project is going to take. Linking effort points to their “time equivalent” will only lead to poor team morale, friction and false expectations, as we have seen before. Avoid that. There is another way to get to time estimates: indirectly!
2.4. In the first few cycles Team Velocity is yet unknown
When planning a cycle (sprint), the team will pick user stories from the top of the backlog until they consider it is enough work for the new cycle. Having a shared Definition of Done can help planning, making sure all team members are aware of all the tasks that have to be completed for each story to be “done”.
Then, during the cycle review you will discover whether all user stories were completed as expected or if there were some changes (e.g. the team was not able to complete all user stories, or by constrast, all stories were completed early and some more were added to the cycle).
As you will see, in the first few cycles there are usually some differences when comparing what the team planned to achieve and what it did actually achieve. However, this error tends to become smaller over time, achieving a similar pace, measured in number of story-points completed per cycle. This metric is often referred to as Team Velocity.
It is worth highlighting the importance of minimizing changes related to team members (eg. replacing someone or changing her dedication). Any change of this sort will have a significant impact on velocity, which would undermine our capacity to forecast release dates.
2.5 After a few cycles you will be able to estimate release dates, based on Team Velocity
So, once a few cycles (sprints) have passed, you will realize that if the team and its story-point estimates have remained consistent, the number of story points being completed per cycle (Team Velocity) is similar.
Since you have been doing your job of keeping the backlog updated, prioritized and estimated in story points, now you will be able to forecast when will a particular story be finished.
An example will make it clearer:
Let’s say our development team is applying the strategy described in this post. It is completing about 25 points per cycle and each cycle is 15 days long. If you want to know when will a particular user story be finished, all you need to do is count the number of story points that are above it in the backlog, add its own story points and do some simple math:
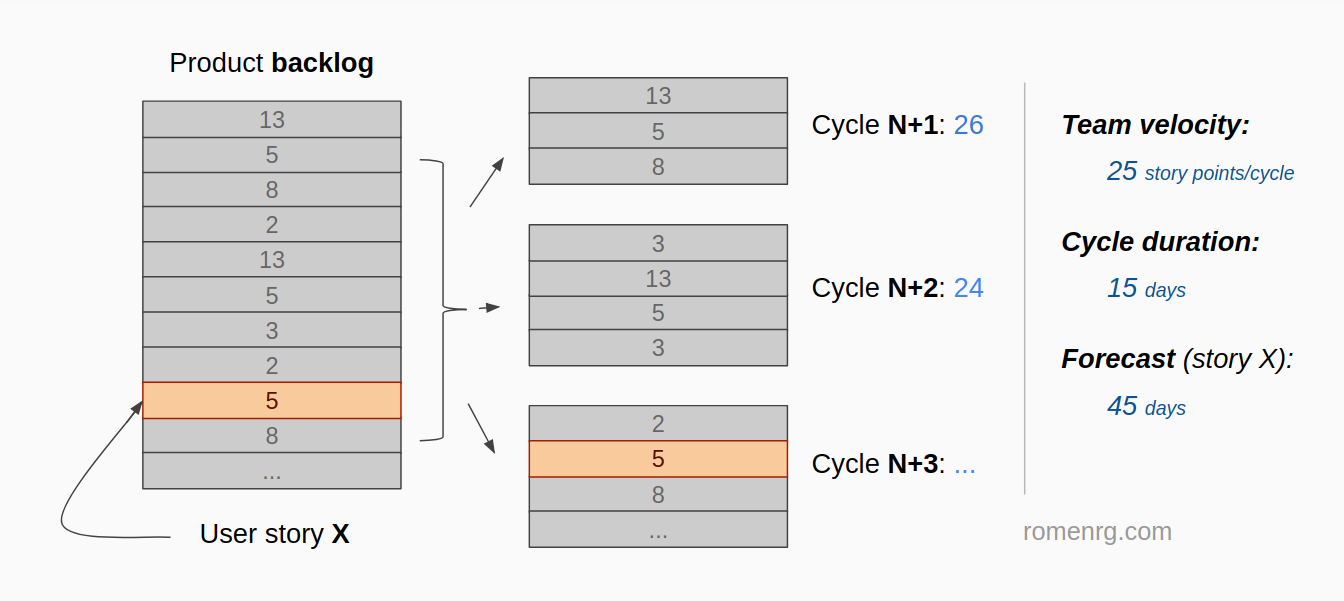
In this example, user story X has 52 points above it in the backlog and has 5 points itself. This means a total of 57 story points have to be completed for story X to be finished. Since in each cycle the team is completing approximately 25 points, the story you are looking for will probably be finished in 3 cycles time, meaning it would be deployed in about 45 days.
The same process can be applied to guess when could the whole project be finished, just taking the last user story you have in the backlog for the calculations explained before.
Conclusion
There is no silver bullet in software estimation. However, if you need to prepare marketing actions or respond to a customer, you will probably need at least a rough idea of delivery dates. Following the management approach described in this article, you will get time estimates without asking for them; you will keep team morale high, avoid burnout and improve productivity. Besides, you will be able to automatically forecast the impact of changes in the timing of the project.
This solution contributes to improve business-engineering relationship, improve software quality and reduce costs in the long-run. Besides, if you involve customers in the process, their understanding and trust may improve considerably, making it easier for both parties to deal with change, preventing many deadline-related conflicts.
Now, join the conversation: How do you deal with time estimates in your company?
Significant revisions
2018, May 06: Added an image to the example and improved its description.
2018, May 01: References to 6-week cycles followed by Basecamp and Buffer are included. Also, replaced the term “sprint” by “cycle”, which seems more appropriate to encourage working at a sustainable pace.
2018, Apr 17: Improving title and meta description.
2015, Sep 28: Original version published.